
Blog Articles
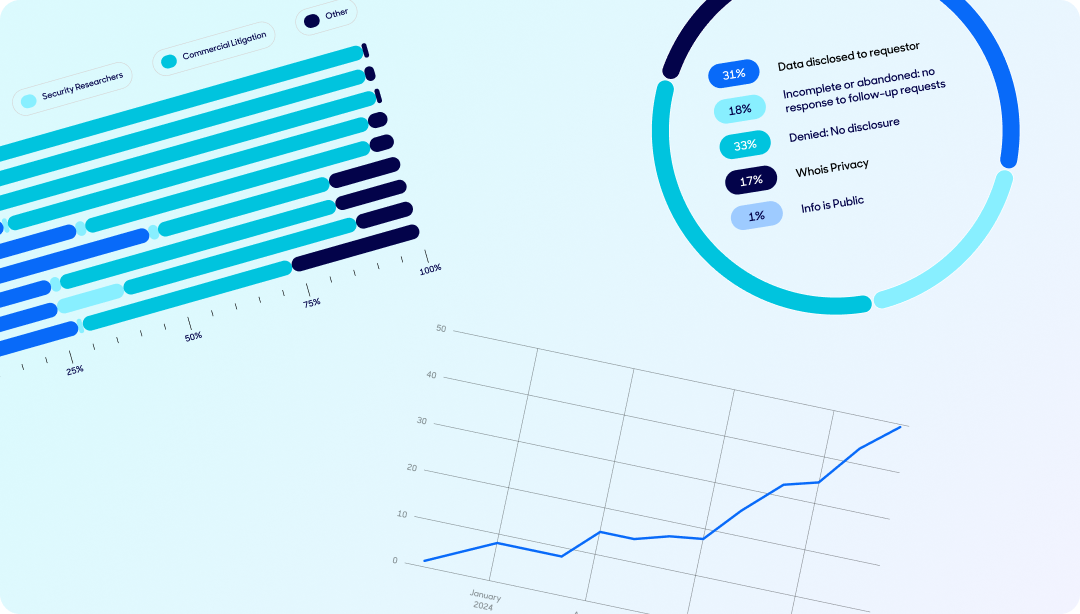
Tiered Access update: CP Summit recap and fresh statistics
ICANN Contracted Parties—domain registrars and registries—met for the CP Summit in Manchester, UK, at the end of April. The two-day agenda covered policy and operational topics so, before delving into our latest TACO stats, we are sharing some highlights from the various sessions and discussions. Day one of the Summit covered operational topics, starting with […]
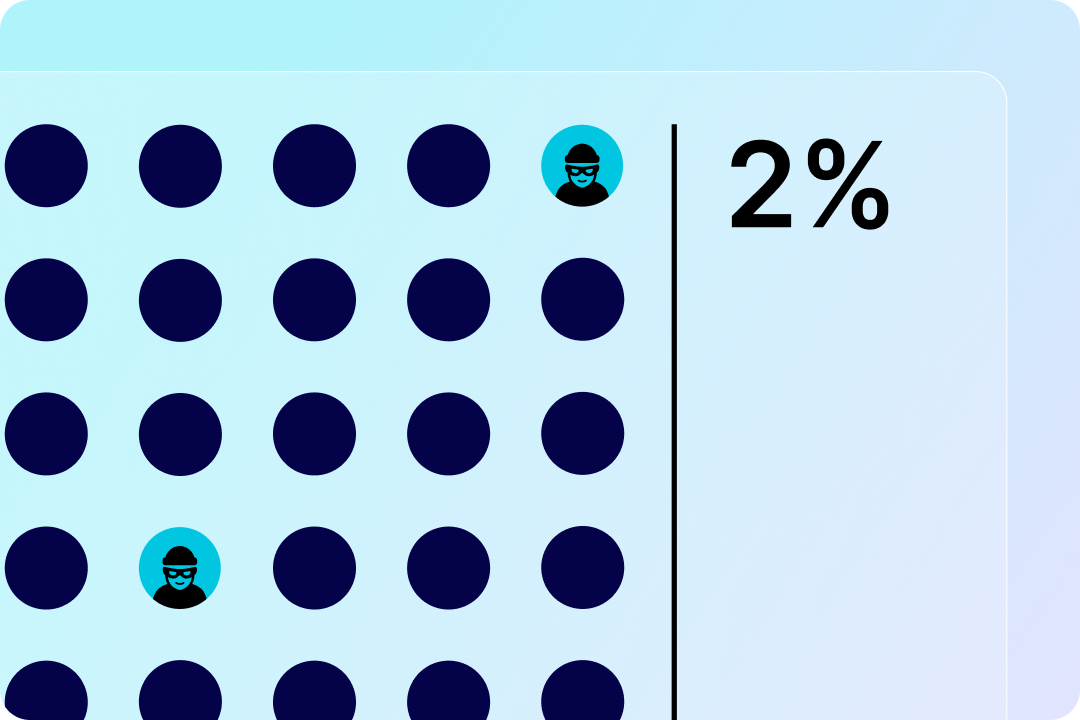
Does Whois verification timing affect DNS Abuse rates?
There has been an idea floating around the ICANN space for a little while now: in an effort to reduce DNS Abuse, we should shorten the period of time registrants have to verify their domains, or have domains remain inactive until verification is complete. But would this change really have a positive effect that’s worth […]
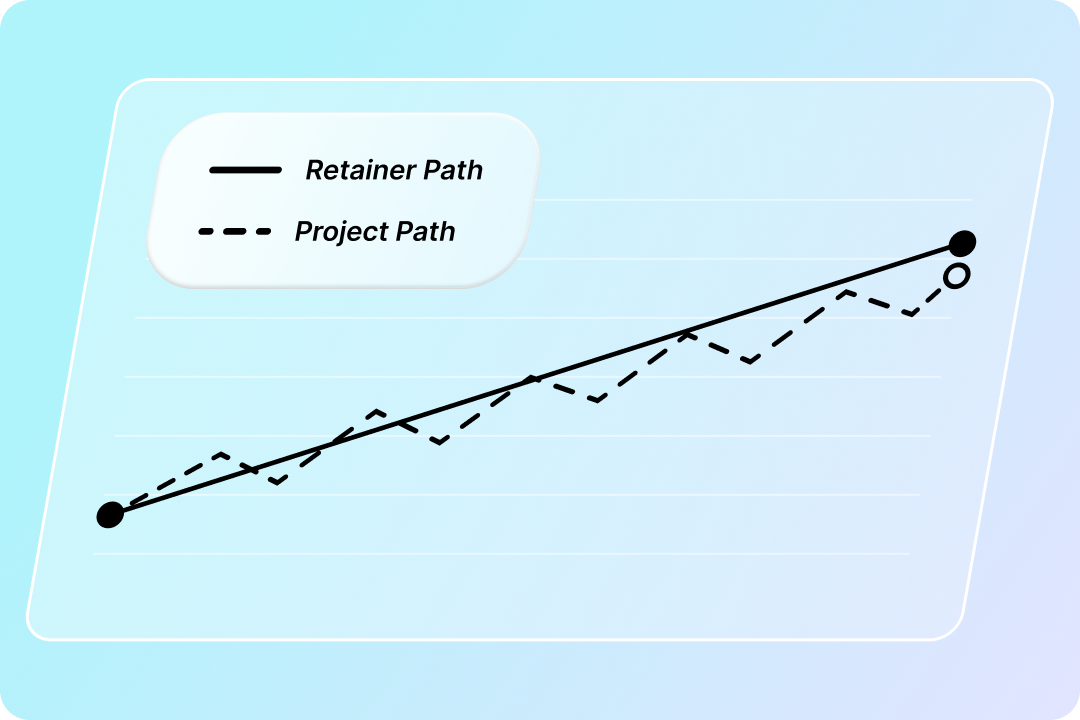
Want to increase client LTV? Start thinking about projects and retainers together
Many agencies and managed service providers (MSPs) operate with a mix of two pricing models: one-time projects and recurring retainers. It’s the right approach, but how you structure that mix can have a significant impact on your financial resilience and overall client value. When we analyzed data from 165 high-performing agencies across the web services […]

How to build and optimize your domain offering as an MSP or agency
In the early days of the Internet, the domain ecosystem was much narrower. A handful of extensions—.com, .net, .org—covered nearly every business online. Today, the Internet looks very different. Entire industries have taken shape online, new niches continue to emerge, and brands are increasingly looking for names that reflect who they are. As the online […]

The overlooked link between acquisition channels and client longevity
When it comes to building long-term profitability as an agency or managed service provider (MSP), who you acquire and how you acquire them can mean the difference between a one-off transaction and a multi-year client relationship. Different acquisition channels set different expectations: some establish trust and context, while others prioritize urgency, price, or convenience. Those […]

ICANN85 Policy Recap
The air-conditioned conference center balanced out Mumbai’s heat and humidity and, despite lower in-person attendance, ICANN85 was a productive meeting. Tucows Registry Services was one of the official meeting sponsors, and we were happy to see many visitors stop to say hello and learn about our registry service offering. Perhaps most importantly, the squishy cows […]
Tiered Access update: A year-over-year review and updated statistics
In 2018, Tucows launched our Tiered Access Compliance and Operations (TACO) platform to manage registration data disclosure requests. From the start, we’ve tracked the requests we receive and committed to publishing this data to promote transparency around access to registrant information. In this post, we’re not only sharing our most recent TACO statistics, but taking […]

How ICPs and buying committees increase client lifetime value
Many agencies and managed service providers (MSPs) struggle to grow client lifetime value (LTV)—not because their services aren’t good, but because they’re selling to the wrong clients or the wrong people inside those organizations. When those two things are clearly defined and understood, client relationships are easier to sustain and expand over time. Agencies and […]
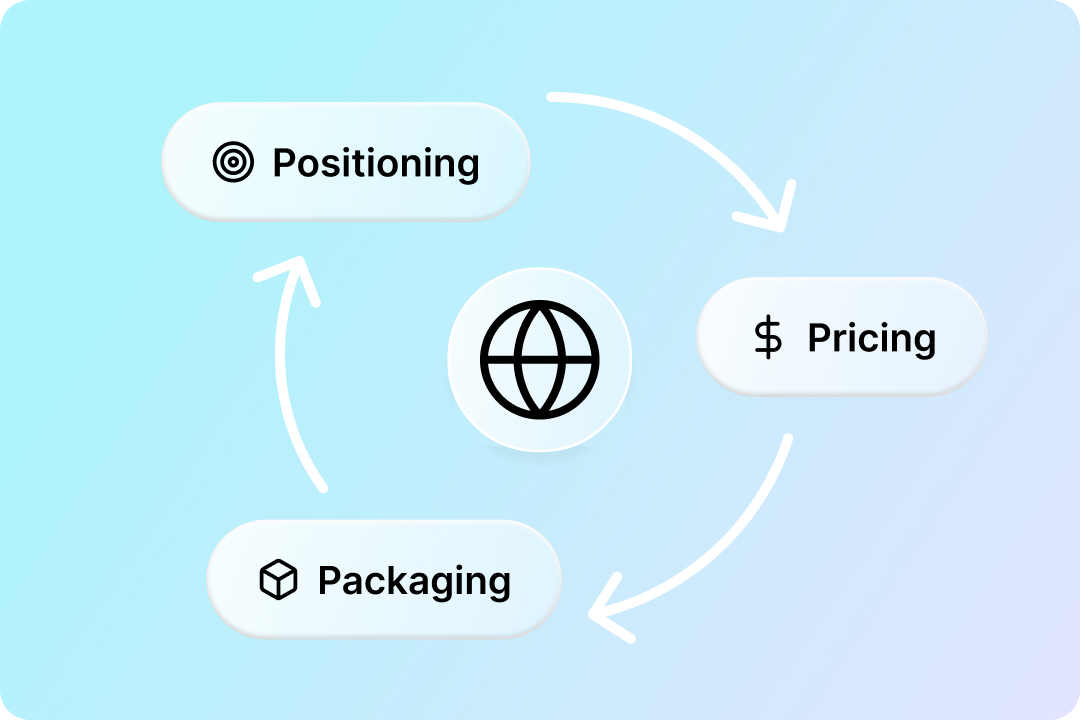
The 3 Ps that drive client lifetime value for agencies and MSPs
For agencies, managed service providers (MSPs), and web professionals, growth isn’t just about winning new clients. It’s about keeping the right ones. That’s where Client Lifetime Value (LTV) comes in. LTV isn’t only a measure of how long clients stick around. It reflects how much value they generate over time, how efficiently you can serve […]

Understanding dot brand TLDs: what they are and why they matter
A strong digital identity starts with your domain—it’s like the front door to your brand online. For decades, businesses have built their presence under top-level domains (TLDs) such as .com, .net, or country-code options like .ca or .uk. In recent years, however, another category has emerged: branded, or “dot brand” TLDs. These give organizations the […]